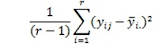A ANVISA pede que, na descrição dos resultados de
um ensaio clínico, seja dada uma estimativa do valor de NNT com
os respectivos intervalos de confiança, para cada intervenção. Mas
o que é NNT? NNT ou Número Necessário Tratar (number needed to treat) é uma medida
de quão eficiente é um tratamento.
Antes de definir NNT, convém lembrar
que:
·
É mostrado
aqui como calcular o NNT, desde que o ensaio compare apenas dois
grupos, como controle e tratado e os desfechos sejam variáveis binárias,
como sucesso ou fracasso.
·
Todas as
circunstâncias que envolvem o ensaio, como duração, dosagens, idade dos
participantes, gravidade da patologia precisam ser mencionadas.
Definição de NNT
NNT é o número médio de pacientes que precisam
receber uma intervenção específica (grupo tratado) para que o desfecho desejado
ocorra em um paciente a mais do que o número que ocorre no controle, mantidas
as mesmas condições.
Informalmente, NNT é o número de pacientes que precisam
ser tratados para evitar um desfecho adicional ruim (morte, infarto, AVC etc.).
Para calcular o NNT, existe uma fórmula. Seja pt a
proporção de sucessos no grupo tratado e pc a proporção de sucessos no grupo
controle, como mostrado na tabela. Então 1- pt é
o risco de fracasso no grupo tratado e 1- pc é
o risco de fracasso no grupo controle.
Proporções de sobrevida e óbito
nos dois grupos

Exemplo 1
Imagine que, para verificar se uma
nova intervenção aumenta a probabilidade de sobrevida, decorridos cinco
anos após o diagnóstico de câncer no pulmão estágio III, foi feito um
ensaio clínico randomizado com 400 pacientes: 200 foram designados para o
controle e 200 para a nova intervenção. Após cinco anos de diagnosticados,
haviam morrido 160 pacientes do grupo controle e 140 do grupo submetido à nova
intervenção, como mostrado na tabela.
Proporção de sobreviventes e mortos,
segundo o grupo
(tamanho de cada grupo =
200)
|
Grupo
|
Desfecho
|
Total
|
Proporção
|
|
Sobrevivente
|
Morto
|
|
Controle
|
40
|
160
|
200
|
pc = 0,20
|
|
Tratado
|
60
|
140
|
200
|
pt = 0,30
|

Mas o que significa NNT = 10? Para
mais bem entender o significado desse resultado, volte à tabela e veja: todos
os números apresentados são divisíveis por 20. Vamos, então, dividir os números
por 20 (o que mantém as proporções).
Proporção de sobreviventes e mortos, segundo o grupo
(tamanho de cada grupo = 10)
|
Grupo
|
Desfecho
|
Total
|
Proporção
|
|
Sobrevivente
|
Morto
|
|
Controle
|
2
|
8
|
10
|
pc = 0,20
|
|
Tratado
|
3
|
7
|
10
|
pt = 0,30
|
NNT = 10: para grupos de 10 pacientes (10 no tratado e 10 no controle), espera-se que sobrevivam 2 no controle e 3 no tratado (1 sobrevivente a mais no grupo tratado). Veja o desenho.
Significado de NNT = 10
Em média, 10 pacientes devem receber a nova
intervenção (em lugar de ser controle) para que seja evitado um óbito a mais
(que teria ocorrido no grupo controle).
Exemplo 2
Pesquisadores
testaram uma nova droga para diminuir a probabilidade de acidente vascular
cerebral (AVC) em homens que sofrem fibrilação atrial. O estudo incluiu 1.000
homens que tomaram a nova droga por cinco anos e 1.000 que receberam a terapia
padrão pelo mesmo tempo. No final do estudo, havia tido acidente vascular cerebral 6% dos homens do grupo da terapia padrão e apenas 2% do grupo que recebeu a nova droga, como mostrado na tabela.
Proporção de pacientes que não tiveram e que tiveram AVC, segundo o grupo
|
Terapia
|
Desfecho
|
Total
|
Proporção
|
|
Sem AVC
|
AVC
|
|
Padrão
|
940
|
60
|
1.000
|
pc = 0,94
|
|
Nova
|
980
|
20
|
1.000
|
pt = 0,98
|

Aplicando a fórmula:
O que significa NNT = 25? É o
número de pacientes que precisam ser tratados para que seja beneficiado um
paciente a mais do que é esperado no grupo controle.
Exemplo 3
Imagine uma doença (1) que depois de instalada
tem, dentro de um ano, risco de morte de 75%. Um tratamento é proposto. É então
conduzido um ensaio clínico com 200 pacientes, divididos igualmente em dois
grupos: controle e tratado. No grupo controle, 75% dos pacientes vieram a óbito dentro de um ano. No grupo tratado, 25% vieram a óbito dentro de um ano. Veja a figura.
Número necessário para tratar
Então, 25% dos pacientes não morreram mesmo sem
tratamento e 25% morreram mesmo tratados. É, portanto, razoável concluir que o
tratamento fez sobreviverem 50% a mais do que sobreviveriam se estivessem no
grupo controle. Logo, o tratamento evita uma morte para cada dois pacientes.
Então NNT = 2, porque se espera que, em média, de cada 2
pacientes tratados, um se beneficie.
Ajuda colocar os dados em tabela ajuda. Veja:
Proporção de sobreviventes e mortos, segundo o grupo
(tamanho de cada grupo = 100)
Aplicando a fórmula:
Significado de valores de NNT
NNT = 100 significa
que 100 pacientes precisam ser tratados para que mais um deles tenha o efeito
desejado.
NNT = 10 significa
que 10 pacientes precisam ser tratados para que mais um deles tenha o efeito
desejado.
NNT = 1 significa
que um paciente precisa ser tratado para que tenha o efeito desejado.
Quanto menor é o NNT, maior é o
benefício da terapia.
NNT = 1 é
o ideal, porque significa que todo paciente tratado é beneficiado.
Redução de risco absoluto (RRA)
(absolute risk reduction)
Redução de risco absoluto (RRA) (absolute risk reduction- ARR)
é uma medida do efeito da intervenção.
Para obter o RRA, calcula-se a diferença
entre a probabilidade de determinado desfecho no grupo controle com a
probabilidade desse mesmo desfecho no grupo submetido à nova intervenção.
O resultado pode ser (ou não) expresso em
porcentagem. Em porcentagem:
Exemplo 4
Imagine que dentro de um ano, o risco de
morte das pessoas com determinado diagnóstico é 0,12. Uma nova droga
reduziu o risco de morte para 0,08 Como se calcula a redução de risco
absoluto (RRA)?
Neste
exemplo, o RRA é 4%. Isso significa que, se 100 pessoas forem
tratadas, espera-se que, dentro de um ano, não morrerão 4. Em outras palavras,
a redução do
risco de morte foi de 4%.
Como se calcula o número necessário tratar (NNT)?
O que significa NNT = 25? Precisam ser tratados 25 pacientes para que seja beneficiado um
paciente a mais do que é esperado no grupo controle.
É importante saber que a redução de risco absoluto (RRA)
(absolute risk reduction) é o inverso do NNT (número
necessário tratar).

Então a maneira mais fácil de calcular o NNT é obter RRA, mas não em termos percentuais, e depois
inverter. No exemplo:

A redução
de risco absoluto (RRA) - também chamada de diferença de risco
(risk difference-RD) - é a maneira mais útil de apresentar o resultado da pesquisa, principalmente se o
leitor for um tomador de decisão.