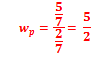1. Média, mediana e moda são...?
- Medidas de significância estatística.
- Medidas de tendência central.
- Medidas de desvio padrão.
- Medidas de erro padrão.
2. Um pesquisador quer estudar os efeitos da música alta na aprendizagem.
Um grupo de 30 alunos é selecionado para participar do estudo. O grupo de estudantes é...?
- A população.
- A variável independente.
- O desvio padrão.
- A amostra.
3. Qual
das seguintes opções não é uma estatística descritiva?
- A renda média de um homem americano de 25 anos é de US $ 22.000 por ano.
- Em 2011, 91% das mortes no local de trabalho aconteceram com homens.
- Os consumidores gastaram US $ 1,2 bilhão em smartphones no ano passado.
- Fumar aumenta a chance de morrer em 37%.
4. Qual
das frases mais bem descreve correlação?
- É um método para determinar a probabilidade de um resultado futuro específico.
- É um método para descobrir relações causais.
- É um método para medir o grau de relação entre variáveis.
- É um método para analisar diferenças entre os grupos.
5. A média de uma distribuição de dez escores é 6. Existem dois escores na distribuição que são iguais a 6.
Você os remove. A média agora é:
- Maior que 6.
- A mesma.
- Menor que 6.
- Não há dados suficientes para saber.
6. O que é uma
amostra aleatória?
- Um conjunto de unidades retiradas de uma população onde algumas unidades têm maior probabilidade do que outras de serem tomadas para a amostra.
- Um conjunto de unidades retiradas de uma população de forma não estruturada.
- Um conjunto de unidades retiradas de uma população onde cada unidade da população tem probabilidade aleatória de compor a amostra.
- Um conjunto de unidades retiradas de uma população onde cada unidade na população tem a mesma probabilidade de compor a amostra.
7. O
que é amplitude de uma distribuição?
- A distância entre o menor e o maior valor.
- A distância entre a média e o maior valor.
- A distância entre a moda e o valor mais alto.
- A distância entre a mediana e o valor mais alto.
8. Um
pesquisador classifica o estresse dos participantes de uma pesquisa em uma escala de 0 a 10. Qual
é o nível de medição?
- Discreta.
- Ordinal.
- Nominal.
- Contínua.
9. Se,
em um teste, você tiver nota igual ao 40º percentil...
- 40% das pessoas tiveram nota igual maior que a sua.
- Sua nota no teste foi 60%.
- O resultado do teste foi de 40%.
- 40% das pessoas tiveram nota igual ou menor que a sua.
10. Um pesquisador
está analisando o efeito do cansaço físico sobre o resultado dos alunos em uma
prova. Qual é a variável dependente?
- O tamanho da amostra do estudo.
- O nível da variável de cansaço.
- O grupo de controle.
- O resultado dos alunos em uma prova.
As questões (e as respostas) deste teste você
encontra, em inglês, em
O teste pretende ser um auxílio de estudo para
estudantes das ciências sociais e humanas, seguindo o conteúdo padrão dos
programas de estatística desses cursos nos Estados Unidos. Se quiser, me
pergunte as respostas.