
Y = a + b X + e
Regressão linear simples é um método estatístico que permite estudar a
relação entre duas variáveis quantitativas, que chamaremos de X e Y.
X é a variável explicativa
ou independente.
Y é a variável resposta ou
dependente.
A regressão
linear simples recebe o nome
de “simples” porque trabalha como uma só variável explicativa. Quando a variável
resposta é função de duas ou mais variáveis explicativas, a regressão linear é
múltipla.
EXEMPLOS
1.
Dados peso e
altura de pessoas adultas, você pode pensar em uma regressão linear simples que coloque
peso como função da variável altura. Então peso é a variável dependente e altura a variável independente.
2.
Dados peso e
altura de pessoas com 6 a 10 anos de idade, você pode pensar em uma
regressão linear múltipla que coloque peso com variável resposta (ou dependente) de duas
variáveis explicativas (ou independente): idade e altura.Em outras palavras, o peso de uma criança depende da idade e da altura.
RELAÇÕES DETERMINÍSTICAS E RELAÇÕES PROBABILÍSTICAS
Antes de continuar, é preciso lembrar que duas variáveis, X e Y,
podem ter uma relação
determinística, ou seja, matemática, como é a relação entre
graus Fahrenheit e graus Celsius:

Quando
colocados em diagrama de dispersão, os pontos caem exatamente sobre uma reta,
como mostra a Figura 1. Isto acontece porque a equação da reta é a descrição
exata da relação entre as duas variáveis.
Figura 1
Diagrama de dispersão: pontos sobre uma reta

Vamos
estudar aqui a relação estatística entre uma variável resposta Y e uma variável explicativa X.
Para começo de conversa, imagine que o fenômeno que você está estudando é bem
descrito por uma reta porque, quando coloca os dados empíricos em um diagrama
de dispersão, os pontos formam uma “nuvem” em torno de uma reta. Mas nessa
“nuvem” caberia uma infinidade de retas. Veja a Figura 2, em que X poderia ser, por exemplo, a altura de
pessoas e Y seria o peso. É preciso
traçar, então, a
reta que
melhor se ajusta aos dados. A questão é: qual é a melhor reta?
Figura 2
Diagrama de dispersão: pontos em torno de uma reta

É preciso
estabelecer um critério para determinar a melhor reta, mas qualquer que
seja a reta será sempre apenas uma aproximação para o verdadeiro
fenômeno: não há como fazer previsões exatas com base em dados empíricos.
E temos que nos haver com a questão estatística de estimação dos parâmetros
porque a reta será ajustada usando os dados de uma amostra e não de toda a
população. Quais são esses parâmetros, quando se fala em uma reta?
A
equação de uma reta é dada por
Y = a + b X,
Nessa
equação, a é o intercepto
porque é o valor que Y assume quando X = 0, ou seja, quando a
reta corta (intercepta) o eixo das ordenadas; b é
uma medida da inclinação da reta. Não é preciso saber mais do que isto
para entender a equação de uma reta, mas não custa lembrar você de que b é
a tangente trigonométrica do ângulo q delimitado pela reta de
equação Y = a + bX e
pela reta paralela ao eixo das abscissas que passa pelo ponto a. Veja a Figura 3.
Quando Y é uma variável aleatória, você pode descrever Y em função de X
com o modelo:
Y = a + b X + e
Nesse
modelo, a e b são
parâmetros e e é o erro aleatório. Para
entender o que é o erro aleatório, observe a Figura 3: e é a distância entre a resposta de uma
observação e a reta de regressão para toda a população.
Figura 3
O erro aleatório

Se
você tem dados de uma amostra, pode obter os valores a e b que
estimam os parâmetros a e b da
reta. Mas, para isso, é
necessário fazer algumas pressuposições.
PRESSUPOSIÇÕES BÁSICAS
Pressuposição
1: A
relação entre as duas variáveis é linear.
Você só deve traçar uma reta para descrever um fenômeno se, no intervalo estudado, a relação entre as duas variáveis é expressa por uma reta. Para saber se a reta é, de fato, o modelo adequado para descrever o fenômeno, existem dois procedimentos: ou você conhece a teoria que diz que o fenômeno é linear ou você “vê que a relação é linear”, olhando o gráfico.
Pressuposição
2: A
variabilidade de Y, para qualquer valor dado de X, é sempre a mesma.
A
variabilidade é medida pela variância. Então esta pressuposição estabelece que
a variância de Y é constante, qualquer que seja o valor de X.
Pressuposição 3: O erro de uma
observação não está correlacionado com o erro de outra observação.
As
observações devem ser independentes. O que isto significa? Por exemplo, fazer a mesma pergunta 20 vezes para uma única pessoa não é igual a fazer a mesma pergunta
para 20 pessoas diferentes. No primeiro caso, as respostas não são
independentes: uma pessoa responde da mesma maneira (ou de maneira similar) a
perguntas iguais. No segundo caso, é razoável supor que as respostas sejam
independentes, desde que as pessoas tenham sido retiradas ao acaso da mesma
população ( e não de um grupo fechado).
Pressuposição 4:
Para qualquer valor de X, os valores de Y têm distribuição normal.
Para
qualquer valor de X, os valores de Y têm distribuição normal
ou, o que é o mesmo, os desvios (Y – Ŷ) têm distribuição
normal. Mas esta pressuposição só é essencial para proceder aos testes
estatísticos. Os programas estatísticos geralmente fazem uma análise dos
resíduos. Algumas dessas análises são gráficas e constituem a maneira fácil
de visualizar se os desvios fogem muito da pressuposição de normalidade.
Pressuposição 5: Os valores de X são fixos, isto é, X
não é variável aleatória.
Cabe,
aqui, um comentário: essa pressuposição não é, na realidade, essencial. Em
certas condições, mesmo que X seja uma variável aleatória, pode ser
ajustada uma reta aos pares de valores X e Y.
Estimativas dos parâmetros
Para
obter a e b, você aplica as
fórmulas dadas em seguida ou, melhor ainda, faz os cálculos usando um
computador. A dedução dessas fórmulas será apresentada em nova postagem. As
fórmulas são:

EXEMPLO
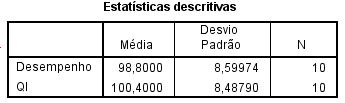
Este exemplo é do tutorial do SPSS:
Uma empresa quer saber se é possível medir o
desempenho no trabalho a partir de escores de QI. A empresa então faz medidas desempenho no trabalho e QI em 10 funcionários. Veja
os dados apresentados na Tabela 1.
Tabela 1
Dados de QI e desempenho de
dez funcionários

Para
obter os valores de a e b, os cálculos intermediários estão apresentados
na Tabela 2.
Tabela 2
Cálculos intermediários para obtenção de a e b

Para obter o valor de b,
é preciso calcular:

Para obter o valor de a,
é preciso calcular as médias de X e de Y:

Então:

Obtidos os valores de a e
b, pode-se escrever a equação da reta:

Agora, é fácil
traçar a reta no gráfico. Basta dar dois valores quaisquer para X (como
zero e 5) e calcular os valores de Y. Para X = 0, tem-se que:

Para
X=5:

De
posse de dois pares de valores de X e Y, é possível construir o
gráfico apresentado na Figura 4.
Figura 4
Reta de regressão

Variâncias dos parâmetros
Para
obter V(b) e V(a),
você aplica as fórmulas dadas em seguida ou, melhor ainda, faz os cálculos
usando um computador. As fórmulas, lembrando que s2 é
um parâmetro, são:

A
questão é obter uma estimativa de s2. Sem aplicar uma
análise de variância, que veremos em nova postagem, você calcula, para o
exemplo que estamos desenvolvendo, a estimativa de s2:
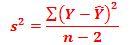
A
Tabela 3 apresenta os cálculos intermediários para obter s2. Lembre-se de que os valores estimados da reta são
dados por

Tabela 3
Cálculos intermediários para obtenção de s2


Você
obtém o erro padrão de a e de b extraindo a raiz quadrada das respectivas
variâncias. Para o exemplo:

Para
testar as hipóteses de que os parâmetros a e
b são iguais a zero, contra
as alternativas de que são diferentes de zero, aplique o teste t ao nível de significância desejado:

Compare
os valores calculados de t com os
valores da distribuição de t com n-2 graus de liberdade e ao nível de
significância estabelecido.
Para
o exemplo que estamos desenvolvendo:

No
nível de 5% de significância e com n-2=8
graus de liberdade, t = 2,306. Logo,
a hipótese de que b =
0 deve ser rejeitada.
Você
pode, também, obter os intervalos de confiança para os parâmetros a e b. Sendo t0 o valor crítico de t com n-2 graus de liberdade e ao nível escolhido de significância, você ontem
os intervalos como segue:

Para
o exemplo:

Se você usar o SPSS, vai obter, para o que foi visto aqui:

VEJA REGRESSÃO LINEAR PASSANDO PELA ORIGEM EM OUTRA POSTAGEM.












