
RESUMO
Quando
a ANOVA indica diferenças significativas entre grupos, o próximo passo é
identificar quais grupos diferem entre si. Se os grupos têm tamanhos desiguais
(amostras desbalanceadas), o teste de Tukey-Kramer é uma escolha confiável e
robusta. Neste post, explicamos como aplicar esse teste passo a passo, com um
exemplo real e a interpretação dos resultados.
1.
INTRODUÇÃO
Quando o pesquisador obtém
um resultado significativo na ANOVA (Análise de Variância) para um experimento
com três ou mais grupos, procura um teste para comparar as médias e identificar
quais delas são estatisticamente diferentes.
Diversos testes estão
disponíveis para esse fim. Esta postagem trata o teste de Tukey-Kramer,
recomendado para situações em que os grupos têm tamanhos diferentes. Nessas
situações, para comparar as médias é preciso substituir o tamanho comum dos
grupos (n) pelos tamanhos (ni e nj)
de cada par que está sendo comparado.
Para aplicar o teste de
Tukey-Kramer, é feita a pressuposição de variâncias homogêneas
(homocedasticidade). Então o quadrado médio do resíduo (QMR), obtido na tabela
ANOVA, é a estimativa da variância comum da variável.
COMO FAZER O TESTE
A diferença
mínima significativa entre as médias de dois grupos de tamanhos ni
e nj, inndicada por di,j é calculada pela fórmula:
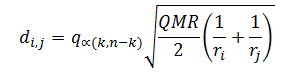
Onde:
· q(k,gl,α) é o valor crítico
da amplitude estudentizada;
·
k é o número de grupos;
· n-k é o número de graus de
liberdade do resíduo na ANOVA;
· QMR é o quadrado médio do resíduo;
· α é o nível de significância.
EXEMPLO
A Tabela 1
apresenta os dados de um experimento com quatro grupos (quatro marcas de chá
verde). As médias de cada grupo estão indicadas ao final da tabela. O objetivo
é comparar essas médias utilizando o teste de Tukey-Kramer. Para isso, é
necessário realizar, primeiramente, uma ANOVA, que está apresentada na Tabela
2.
Em seguida,
realizam-se as comparações par a par das médias das marcas. Para aplicar o
teste, utilizou-se o valor de q para um nível de
significância de 5%, com k = 4 grupos e gl = n-k = 24-4 = 20 graus de liberdade do resíduo.
Tabela
1: Conteúdo
de ácido fólico (vitamina B) em folhas de chá verde selecionadas aleatoriamente
de quatro marcas (1)

Tabela 2: Análise de variância dos dados da Tabela 1

Por exemplo:
· Para comparar a média da Marca 1 com a da Marca 2 (no nível de significância de 5%, calcula-se

· Para comparar a média da Marca 1 com a da Marca 3, o
procedimento é análogo, usando n1 =7 e n3 =6.
O mesmo
procedimento é repetido para os demais pares. A Tabela 3 apresenta as
diferenças observadas entre as médias e os respectivos valores de dij. Quando a diferença absoluta entre duas médias for maior que
seu dij. correspondente,
rejeita-se a hipótese de igualdade entre essas médias (H₀: μi = μj).
Tabela
3: Comparação
de médias pelo teste de Tukey-Kramer

Interpretação
A
interpretação dos resultados da Tabela 3 indica, por exemplo, que a Marca 1
apresenta, em média, teor de ácido fólico significativamente maior que o da
Marca 4.
APROXIMAÇÃO COM A MÉDIA HARMÔNICA
O cálculo de todas as
diferenças mínimas significativas pelo teste de Tukey-Kramer pode ser
trabalhoso manualmente. Com softwares estatísticos, esse processo é
automatizado. No passado, para simplificar o cálculo quando os tamanhos dos
grupos eram aproximadamente iguais, era comum adotar uma aproximação: utilizar
a fórmula tradicional do teste de Tukey, substituindo n pela média harmônica (H) dos tamanhos
amostrais. A fórmula se torna:

Essa
abordagem é uma aproximação, e o controle do nível de significância pode não
ser exato, mas pode ser encontrada em trabalhos mais antigos.
Com os dados
da Tabela 1, onde os tamanhos dos grupos são 7, 5, 6 e 6, a média harmônica H é calculada por:

Então:

Substituindo
os valores, obtém-se um valor único de d para todas as
comparações. Neste exemplo, a interpretação dos resultados usando essa
aproximação permanece coerente com a análise completa.
Literatura




















